

Python爬虫用bs4模块爬取中国天气网天气信息
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式;Beautiful Soup会帮你节省数小时甚至数天的工作时间。
虽然就我个人而言更喜欢用xpath的方式来解析页面,但不得不说bs4也是一种非常方便的方式,尤其是像一些结构工整的标签,如ul>li,table>tr>td等。
没错,这是我们python课的一次实践
一、信息爬取
1.各地区下各城市七天天气
(1)首先先给出要爬取的链接文字版国内城市天气预报|地图版国内城市天气预报(ps:我还真就没在主页找到这个链接的入口,还是上网查到的…)
(2)右键审查元素,分析页面结构,发现它是由七个div(class=”conMidtab”)构成,分别对应从今天开始的七天天气情况。每个div(class=”conMidtab”)中又由5个div(class=”conMidtab2”)组成,分别对应华北地区的五个省市,div(class=”conMidtab2”)下的table标签就是我们要获取的天气情况数据了,tr0和tr1分别是昼夜和天气的标题,从tr2(即第三个tr因为从零开始与代码对应)开始才是我们需要的信息,又发现tr2中有9个td标签,tr3以后只有8个td标签,原因是将省市一列放进了tr2中,及tr2>td0。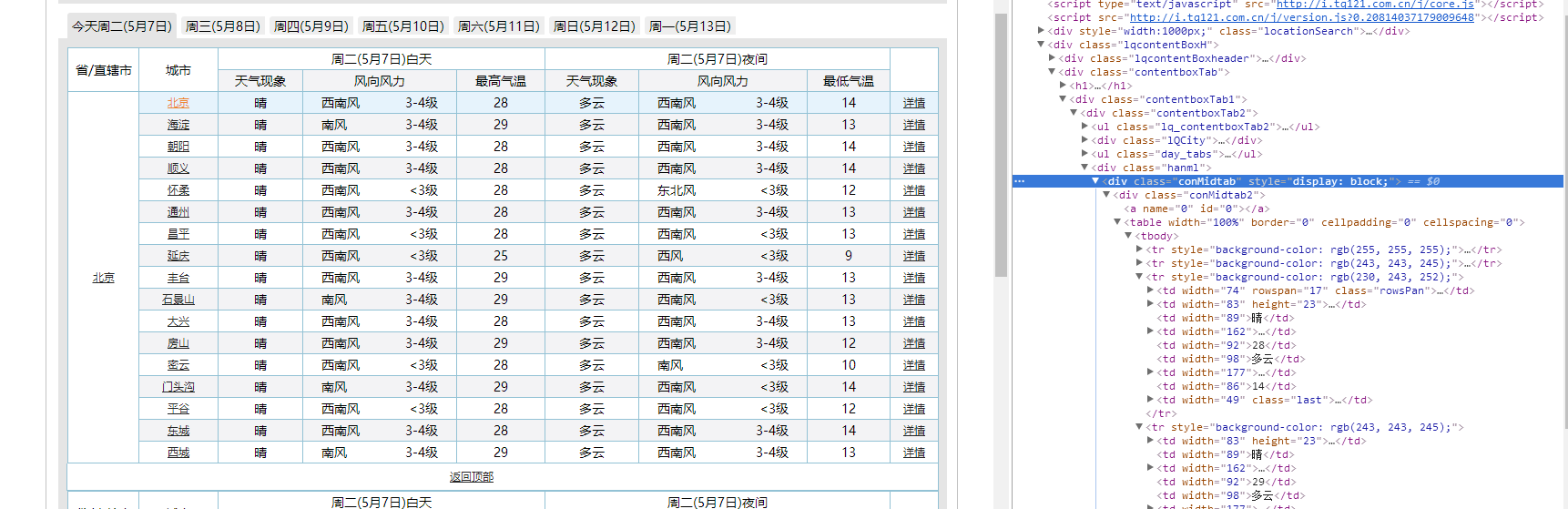
(3)先写一下针对当天华北地区下各城市的天气情况的爬取
1 | headers = { |
上述代码运行成功结果如下
(4)将url改为列表拼接形式测试所有地区的情况
1 | def main(): |
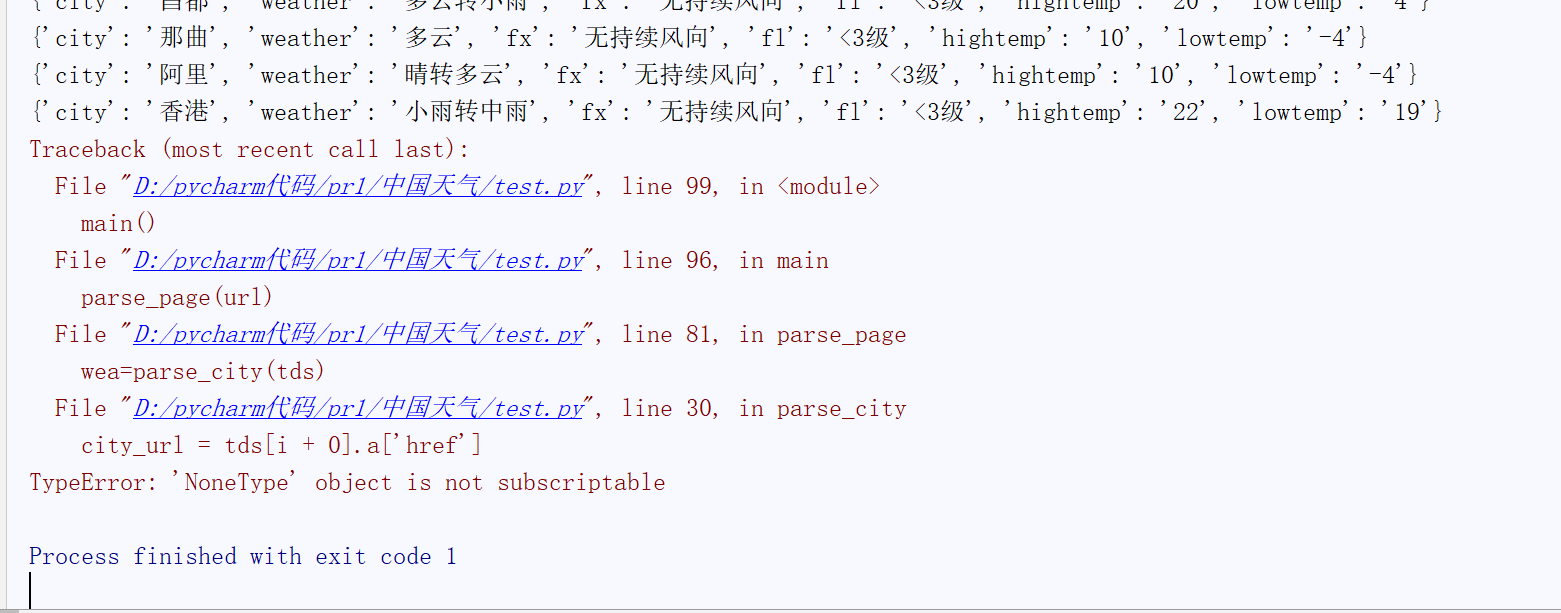
可以发现前面的都可以正常运行,直到这个位置,香港之后的会报错。
我们去看一下港澳台地区的页面结构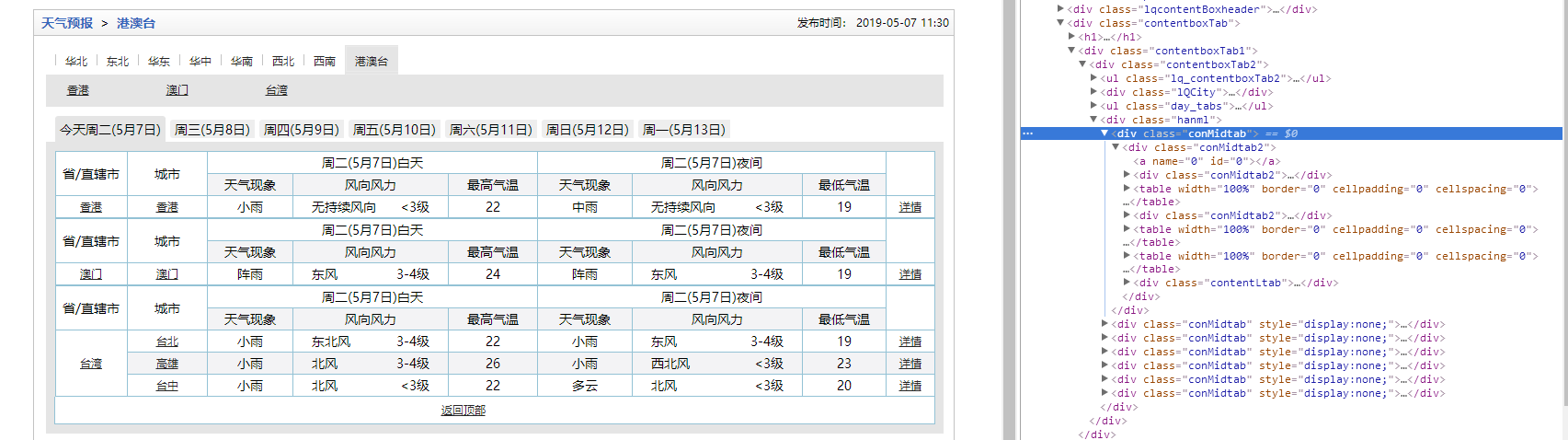
可以发现香港澳门只有一个城市,所以在进不去tr3之后的for循环,可以看到代码中我获取的province一列还没有用上,既然香港澳门特殊我就把他排除还不行吗?
刚开始我是这么写的
1 | if province!='香港' or province!='澳门': |
然后发现province也有换行符改为province1:3,字符串截取一下。
然后运行发现报错依旧,我又以为是province获取到的是utf-8,而python中是Unicode,匹配不了?(ps:真正原因并不是这个,当时想多了),又改为匹配省市的链接然后判断。
1 | p_url=firsttds[0].a['href'] |
报错是没了,但是会输出7组港澳台的城市,这并不是我们想要的,经过我一点一点排查,debug分析终于找到了问题的根源所在。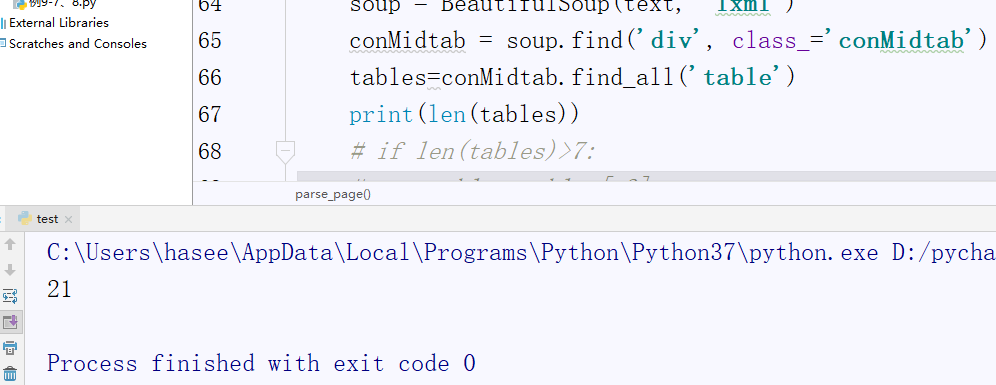
在获取港澳台地区的信息的时候他匹配的table数是21个即所有七天的表格数据,经查看发现省市最多地区的省市有7个就是tables最多七个,于是我添加了以下代码针对gat对tables做了下处理。
1 | if len(tables)>7: |
然后再运行,成功!
(5)获取每个城市七天的天气情况及获取地区下省市信息
我是通过一个m变量然后每次循环递增,并只在m==0的时候输出地区下的省市城市信息
当然还有一种方式是在天气情况字典中添加日期一行这样来区分七天天气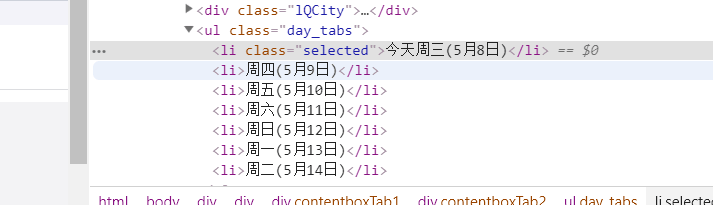
1 | dateul=soup.find('ul',class_='day_tabs') |
(6)获取城市天气源代码
1 | import requests |
2.获取各城市下周边城市天气情况
(1)点击城市进入城市天气主页,查看其周边城市的结构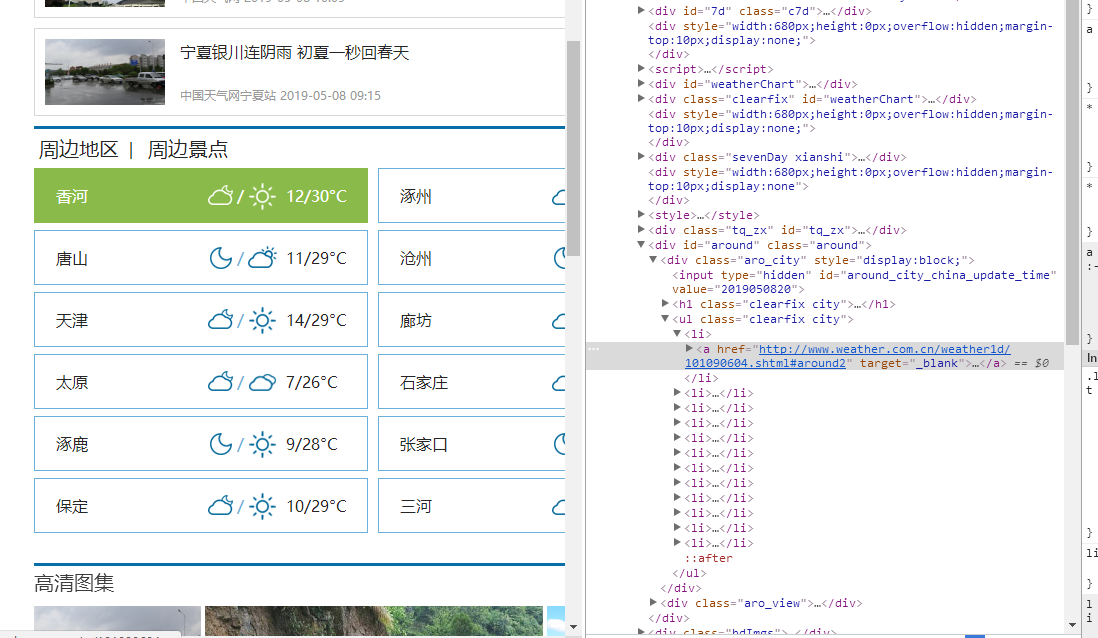
然后点击进入发现只是今天的天气情况,点击七天,对比两个网址发现城市的代码是不变的。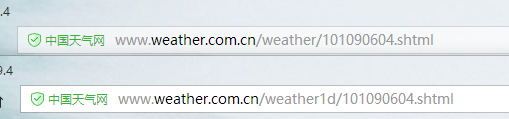
首先获取周边城市的链接,然后用正则表达式提取出其中的城市代码,最后改变链接访问城市七天天气界面。沿用获取地区下城市的方法用参数i将第一个城市分开。
1 | def nearcitycode(tds,i=0): |
(2)上述代码拿到周边城市代码及对应城市,分别放在两个列表中返回。
针对每个周边城市的七天天气情况页面解析,获取需要的数据
1 | n=[] |
(3)对每个城市进行遍历的结构基本不变,只是将parse_city变为_nearcity去掉local字典
1 | def parse_page(ur,dir): |
(4)最后附上周边城市源码,由于之前的方法每个城市都要遍历列表n,运行时间比较长,但是可区分每个的周边城市信息,后更改为n接受所有的代码然后用list(set(n))去重在解析统一输出,只不过会变成无序。
1 | import requests |
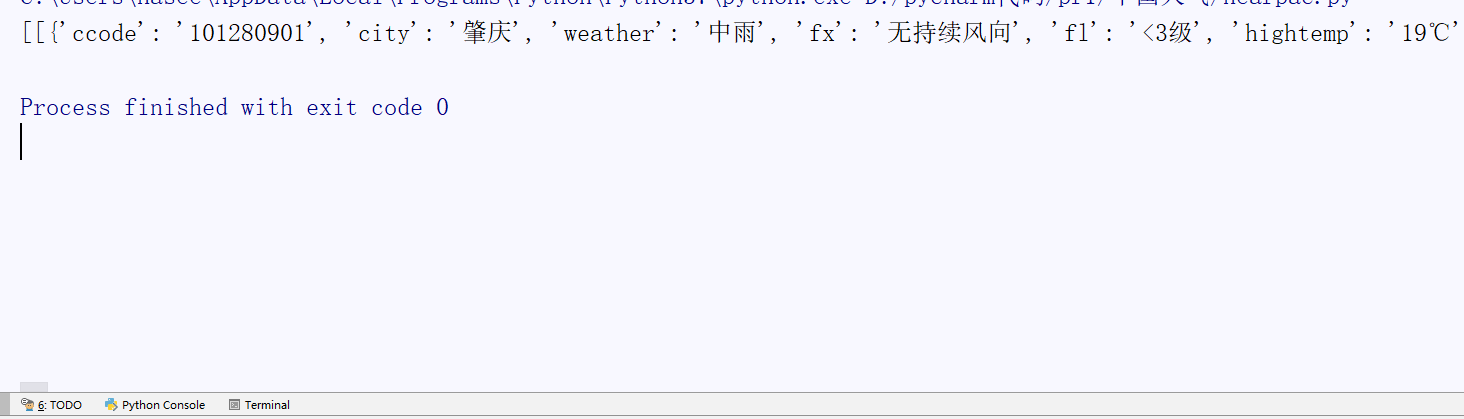
测试了一下城市最少的港澳台,成功!
二、添加数到数据库,以oracle为例
1 | # 视个人情况更改 |
最后就可存入到本地的oracle数据库中了。

