

Python爬虫携带cookie访问页面详解
cookie,指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)。其实就是浏览器用来记录网页登录状态以便下次再次登陆的时候可以直接通过cookie登录。
那么对于爬虫来说如果要访问一些需要个人登录才能进入的页面,携带cookie必不可少,今天我就来详细介绍一下爬虫如何携带cookie进行页面访问。
一、首先这个cookie要如何获得呢,以人人网为例这里给两种方法:
1、浏览器中审查元素,在network中获取
(1)首先确保你有一个人人网的号(没有先注册一个),浏览器中访问人人网,右键审查元素,network,记得要勾选Preserve log,意思是保留上一个页面的访问过程,由于cookie是在登陆之前获取的,如果不勾选,点登录后会直接跳转到新页面记录新页面的加载过程,从而无法找到登陆的cookie。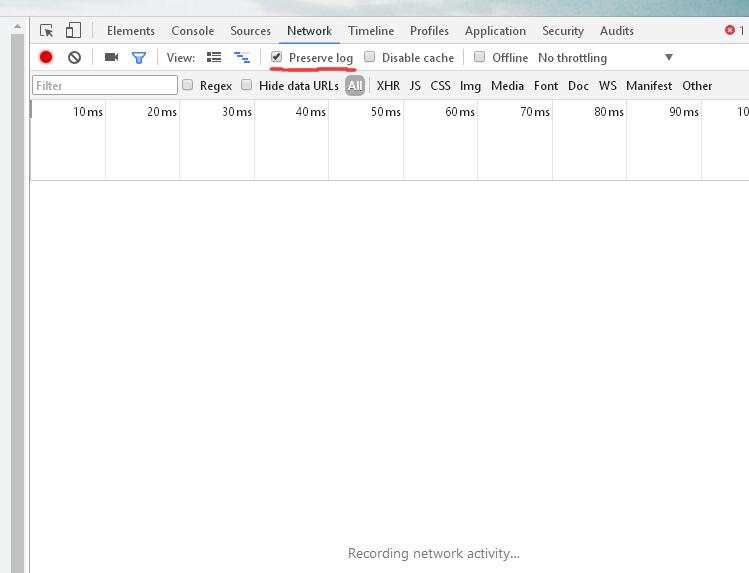
(2)点击登录,找到带login字样的进程一般在前几个。点击查看右侧的request headers中的cookie。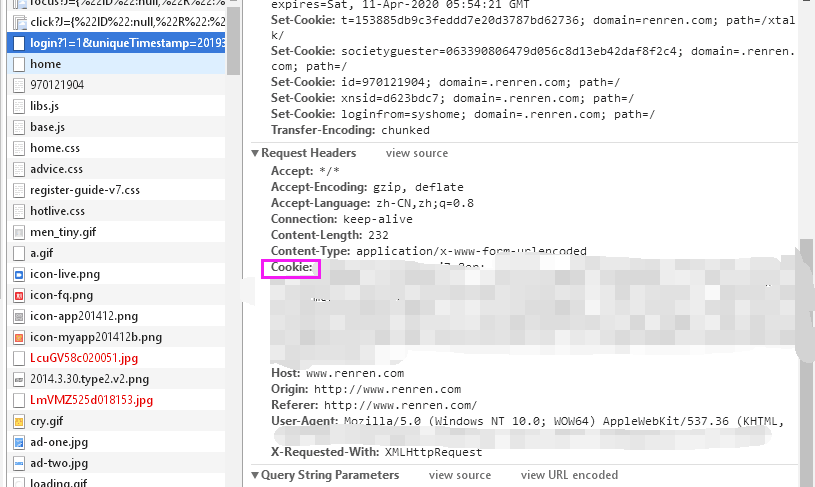
2、通过工具(Fiddler)对访问进行抓包处理。
这里给一个汉化破解版的Fiddler,如果有其他需要可以自行百度。
简单说一下操作,在抓取你所需的网页信息之前,先暂停捕获/F12,然后再左侧下面的输入框中输入clear,清除已经捕获到的其他网页信息,然后开始捕获/F12,并回到浏览器点击登录,待信息跳转频率变慢或不在跳转,暂定捕获,查找你要找的界面信息。这里会分类全面的展示页面的相应信息,消息头,cookie,表单数据等。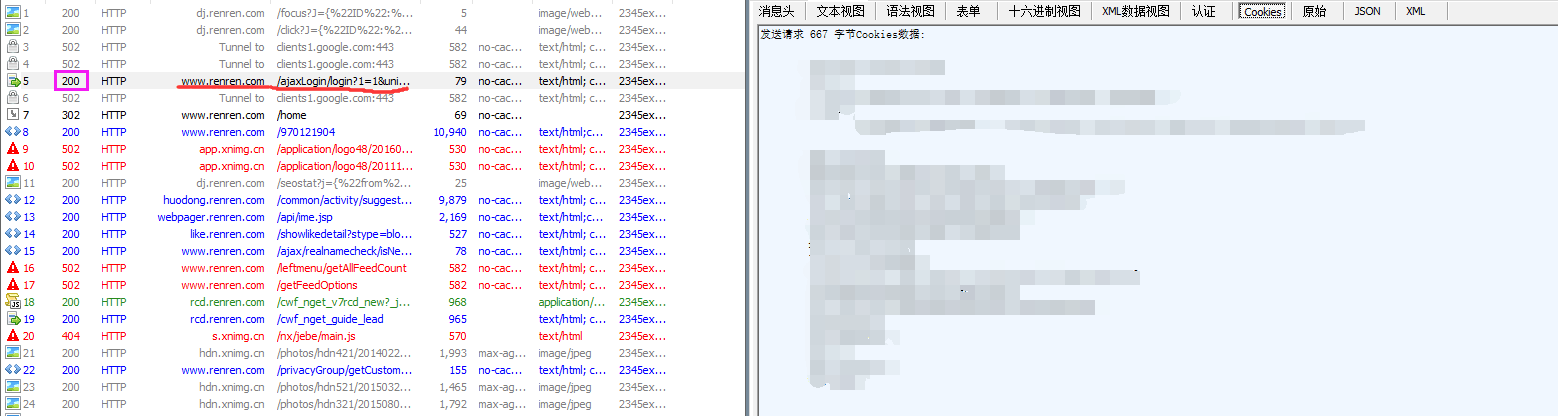
二、几种携带cookie访问登陆的方式,以访问个人页面为例,并将结果写入html文件中,便于观察。
1、直接在消息头/headers添加cookie通过urllib方式访问:
1 | import urllib.request |
2、用cookiejar库动态获取并保存cookie,通过urllib方式访问:
1 | import urllib.request |
3、通过requests模块,进行带cookie访问:
直接在cmd中运行pip install requests即可安装requests模块
1 | import requests |
4、requests模块登录并保存cookie,再去访问个人页面。
1 | import requests |
最后推荐使用2,4两种方式来进行这种带cookie的爬取操作,因为从网页上抓包获取到的cookie是有时间戳的,过段时间就会过期,2,4这种动态获取cookie的方式比较实用稳定。

