

k-近邻算法实战之sklearn手写数字识别
1、k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。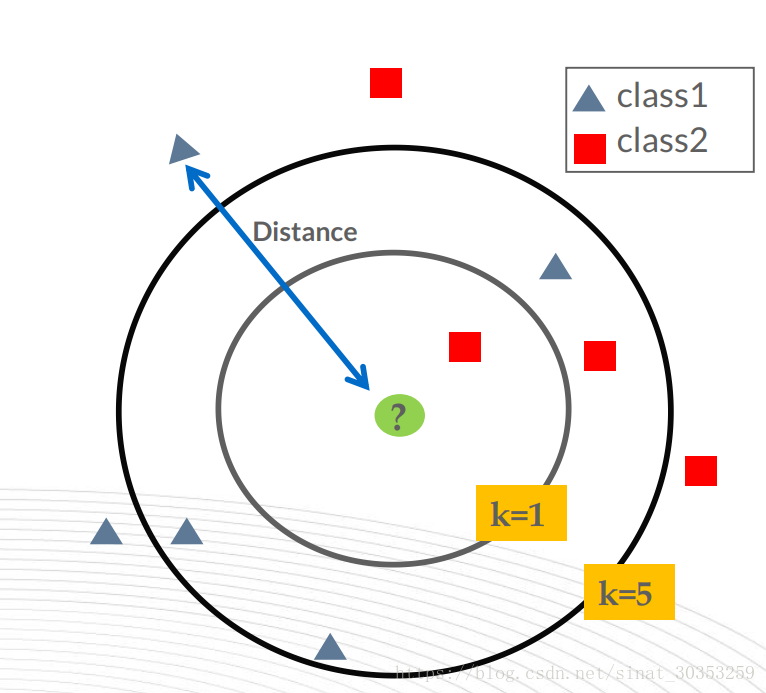
(1)该算法的思想是: 一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别,则该样本也属于这个类别。
(2)距离度量:我们以下图为例,横坐标为打斗镜头,纵坐标为接吻镜头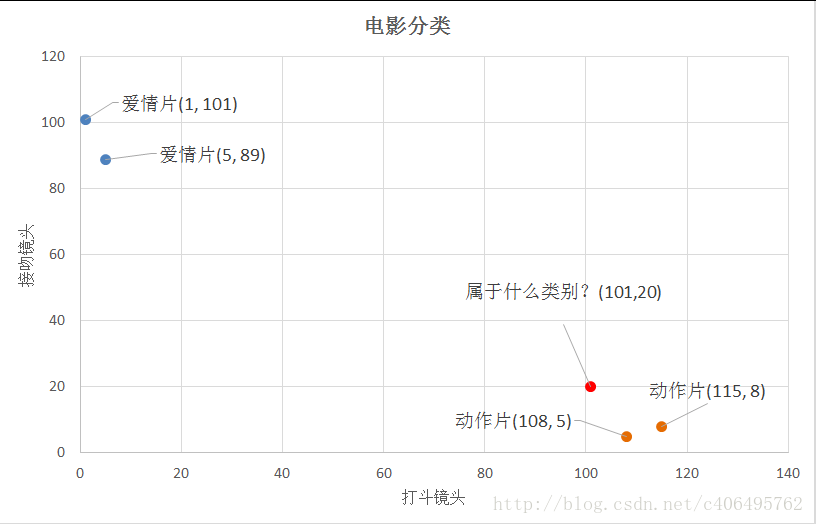
我们可以从散点图大致推断,这个红色圆点标记的电影可能属于动作片,因为距离已知的那两个动作片的圆点更近。k-近邻算法用什么方法进行判断呢?没错,就是距离度量。这个电影分类的例子有2个特征,也就是在2维实数向量空间,可以使用我们高中学过的两点距离公式计算距离。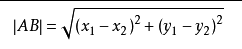
电影例子中的特征是2维的,这样的距离度量可以用两点距离公式计算,但是如果是更高维的呢?对,没错。我们可以用欧氏距离(也称欧几里德度量),如图所示。我们高中所学的两点距离公式就是欧氏距离在二维空间上的公式,也就是欧氏距离的n的值为2的情况。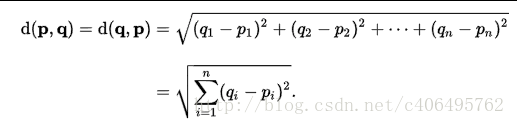
(3)k值选择:
通过计算,我们可以得到如下结果:
(101,20)->动作片(108,5)的距离约为16.55
(101,20)->动作片(115,8)的距离约为18.44
(101,20)->爱情片(5,89)的距离约为118.22
(101,20)->爱情片(1,101)的距离约为128.69
红色圆点标记的电影到动作片 (108,5)的距离最近,为16.55。如果算法直接根据这个结果,判断该红色圆点标记的电影为动作片,这个算法就是最近邻算法,而非k-近邻算法。那么k-邻近算法是什么呢?k-近邻算法步骤如下:
1)计算已知类别数据集中的点与当前点之间的距离;
2)按照距离递增次序排序;
3)选取与当前点距离最小的k个点;
4)确定前k个点所在类别的出现频率;
5)返回前k个点所出现频率最高的类别作为当前点的预测分类。
比如,现在我这个k值取3,那么在电影例子中,按距离依次排序的三个点分别是动作片(108,5)、动作片(115,8)、爱情片(5,89)。在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以该红色圆点标记的电影为动作片。这个判别过程就是k-近邻算法。
那么对于其他情况来说k值又该如何选择呢?
如果选择较小的K值,就相当于用较小的邻域中的训练实例进行预测,学习的近似误差会减小,只有与输入实例较近的训练实例才会对预测结果起作用,但缺点是学习的估计误差会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪点,预测就会出错。换句话说,K值减小就意味着整体模型变复杂,分的不清楚,就容易发生过拟合。
如果选择较大K值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少学习的估计误差,但近似误差会增大,也就是对输入实例预测不准确,K值得增大就意味着整体模型变的简单
近似误差:可以理解为对现有训练集的训练误差。
估计误差:可以理解为对测试集的测试误差。
近似误差关注训练集,如果k值小了会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型。
估计误差关注测试集,估计误差小了说明对未知数据的预测能力好。模型本身最接近最佳模型。
在应用中,K值一般取一个比较小的数值,通常采用交叉验证法来选取最优的K值。
(4)K-近邻的优缺点
KNN算法的优点:
1)简单、有效。
2)重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
3)计算时间和空间线性于训练集的规模(在一些场合不算太大)。
4)由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
5)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
KNN算法缺点:
1)KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多。
2)类别评分不是规格化的(不像概率评分)。
3)输出的可解释性不强,例如决策树的可解释性较强。
4)该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
5)计算量较大。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
2、k近邻算法的代码实现:
(1)手动编写函数实现
1 | import numpy as np |
classify0为具体写法,一步步进行,classify1为简化写法,毕竟用python怎么能不体现出其精简的优势,同样的代码,python因为其简化写法,进行行数缩减,增加开发效率。在本文的最后给出电影案例的源程序,文件为test0.py
(2)k-近邻算法实战之sklearn手写数字识别(sklearn模块实现)
1)Sklearn简介
Scikit learn 也简称sklearn,是机器学习领域当中最知名的python模块之一。sklearn包含了很多机器学习的方式:
Classification 分类
Regression 回归
Clustering 非监督分类
Dimensionality reduction 数据降维
Model Selection 模型选择
Preprocessing 数据与处理
使用sklearn可以很方便地让我们实现一个机器学习算法。一个复杂度算法的实现,使用sklearn可能只需要调用几行API即可。所以学习sklearn,可以有效减少我们特定任务的实现周期。
2)安装
参见python安装sklearn模块,里面介绍是先安装几个库,然后再pip install,如果你用的是pycharm,可以直接在settings->project xx->Project Interpreter,点击右侧+来进行搜索安装,或者你是用Anaconda安装的python可以用对应的conda命令来安装模块。
3)案例及使用
官网英文文档
sklearn.neighbors模块实现了k-近邻算法,参数如下

要注意数据集的权重对预测结果的影响,像图中的Y,明显属于红点区域,但却因为蓝色三角形区域所占数量更多,会被判为蓝色三角区域类型。
对于需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽高是32像素x32像素。尽管采用本文格式存储图像不能有效地利用内存空间,但是为了方便理解,我们将图片转换为文本格式,数字的文本格式如图所示。
与此同时,这些文本格式存储的数字的文件命名也很有特点,格式为:数字的值_该数字的样本序号
对于这样已经整理好的文本,我们可以直接使用Python处理,进行数字预测。数据集分为训练集和测试集,使用上小结的方法,设计k-近邻算法分类器,可以实现分类。
我们知道数字图片是32x32的二进制图像,为了方便计算,我们可以将32x32的二进制图像转换为1x1024的向量。对于sklearn的KNeighborsClassifier输入可以是矩阵,不用一定转换为向量,,为了方便这里也做了向量化处理。然后构建kNN分类器,利用分类器做预测。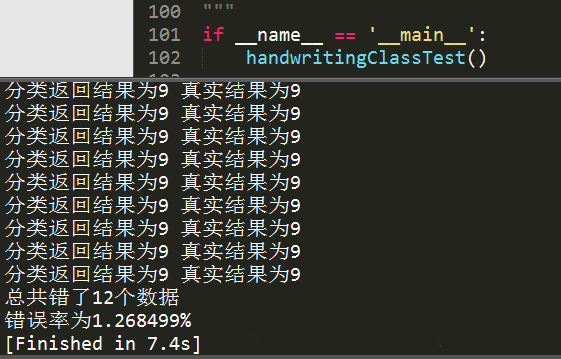
上述代码使用的algorithm参数是auto,更改algorithm参数为brute,使用暴力搜索,你会发现,运行时间变长了,变为10s+。更改n_neighbors参数,你会发现,不同的值,检测精度也是不同的。自己可以尝试更改这些参数的设置,加深对其函数的理解。
以上数据改编于加州大学UCI机器学习库中的
手写数字数据集的光学识别数据集。
最后附上测试数据及全部代码的压缩文档

