
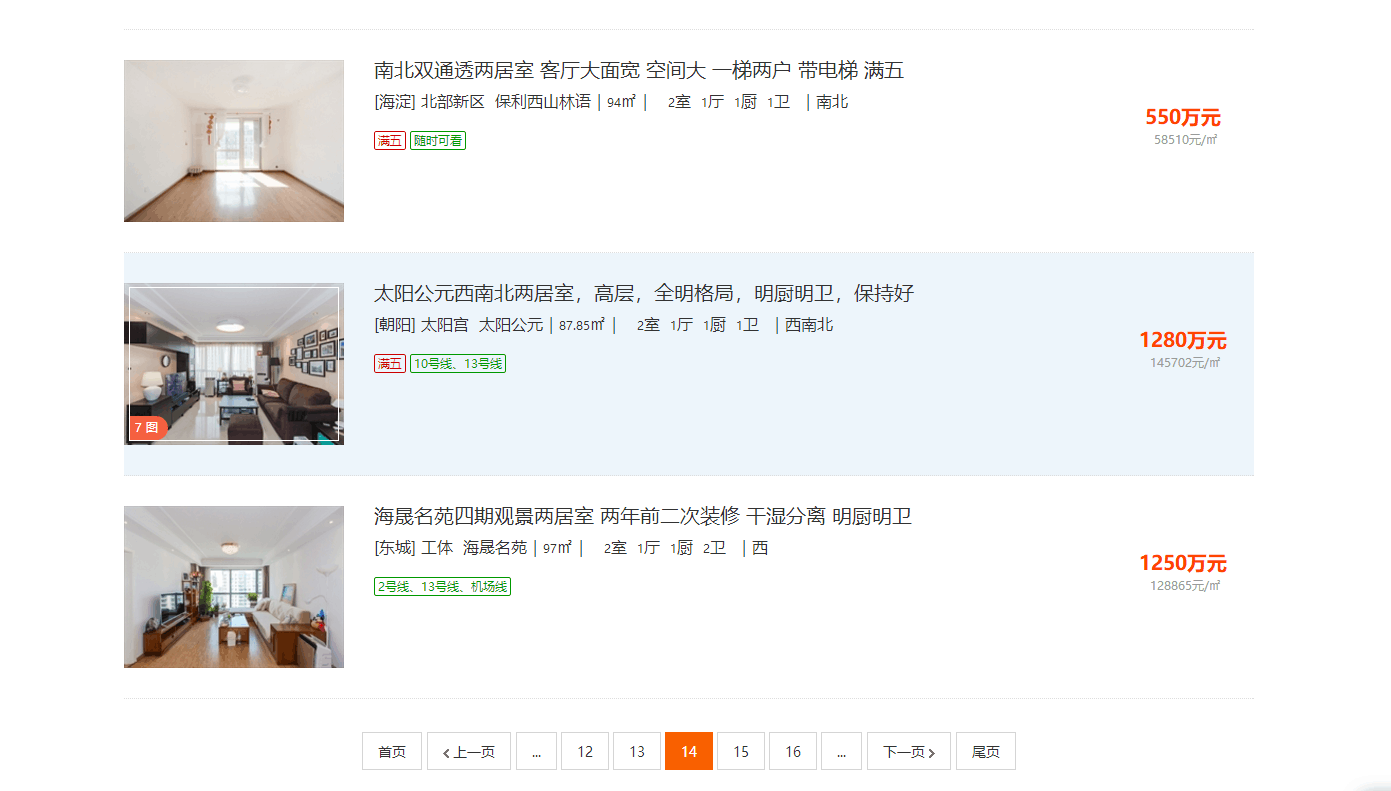
Python爬虫通过Scrapy框架爬取麦田网二手房信息
写爬虫有段时间了,我发现每次写一个新爬虫都会有很多语句与之前写的一样,总是复制粘贴太过麻烦,终于Scrapy框架解决了我的烦恼。
1、安装Scrapy
Scrapy入门教程,入门使用发放参见中文文档。至于安装的方法也很简单,如果有python的环境在cmd下直接运行pip install Scrapy即可,我说一下我遇到的问题
(1)首先我在输入命令行的时候提示’pip‘不是内部命令,原因是我环境变量没有配好。开始菜单中输入idle右键打开文件所在位置,这个是快捷方式的位置,继续右键打开文件所在位置,直至找到你python所在的路径,添加到path中,具体不详述了,解决。
(2)安装过程中报错error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: …,参见博客Scrapy安装包错解决。
(3)如果出现别的错误,请自行百度解决,反正我就遇到了这两个问题。安装完Scrapy之后我还出现了在cmd中运行成功,在pycharm中terminal’Scrapy‘不是内部命令的情况,重启,解决。
然后按照文档所述新建一个为maitian的Scrapy项目,
(1)scrapy startproject maitian
(2)scrapy genspider -t basic s1 maitian.cn
(3)在items.py中添加如下代码,分别对应要获取的元素内容(标题,价格,面积,位置)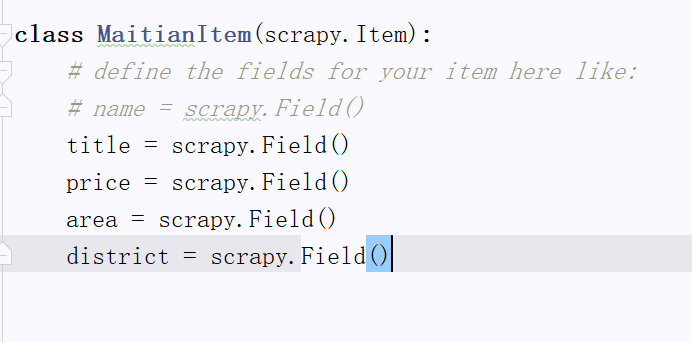
(4)然后再spiders->s1.py中导入,并通过xpath方式获取到对应内容,这里说一个检验页面xpath的浏览器插件。谷歌浏览器可能添加不了,要翻墙在扩展程序商城下载。其他浏览器可直接将压缩文件中的crx拖到浏览器界面即可添加成功。然后重启浏览器,点击上方扩展程序,将所要检测的xpath粘到左边框里,右边框就会展示对应内容,并在页面高亮。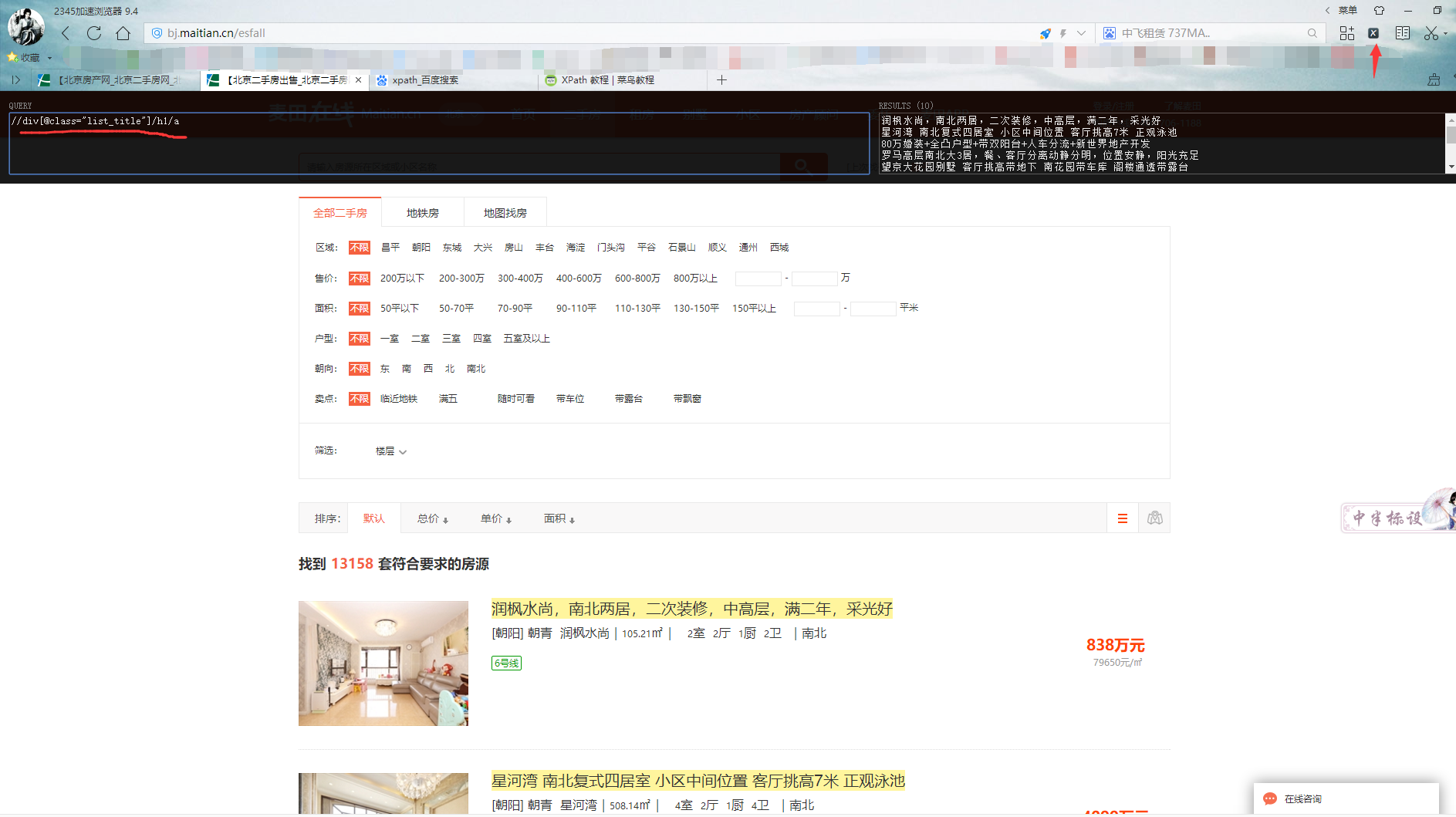
将对应的xpath输入检测,然后再s1.py中通过xpath方式获取到相应内容。通过换页发现翻页是通过PG+页数参数确定的,可以试一下PG1,会发现还是第一页,正常情况下被隐藏了。我设置了一个for循环append到start_urls列表中,实现抓取多页内容。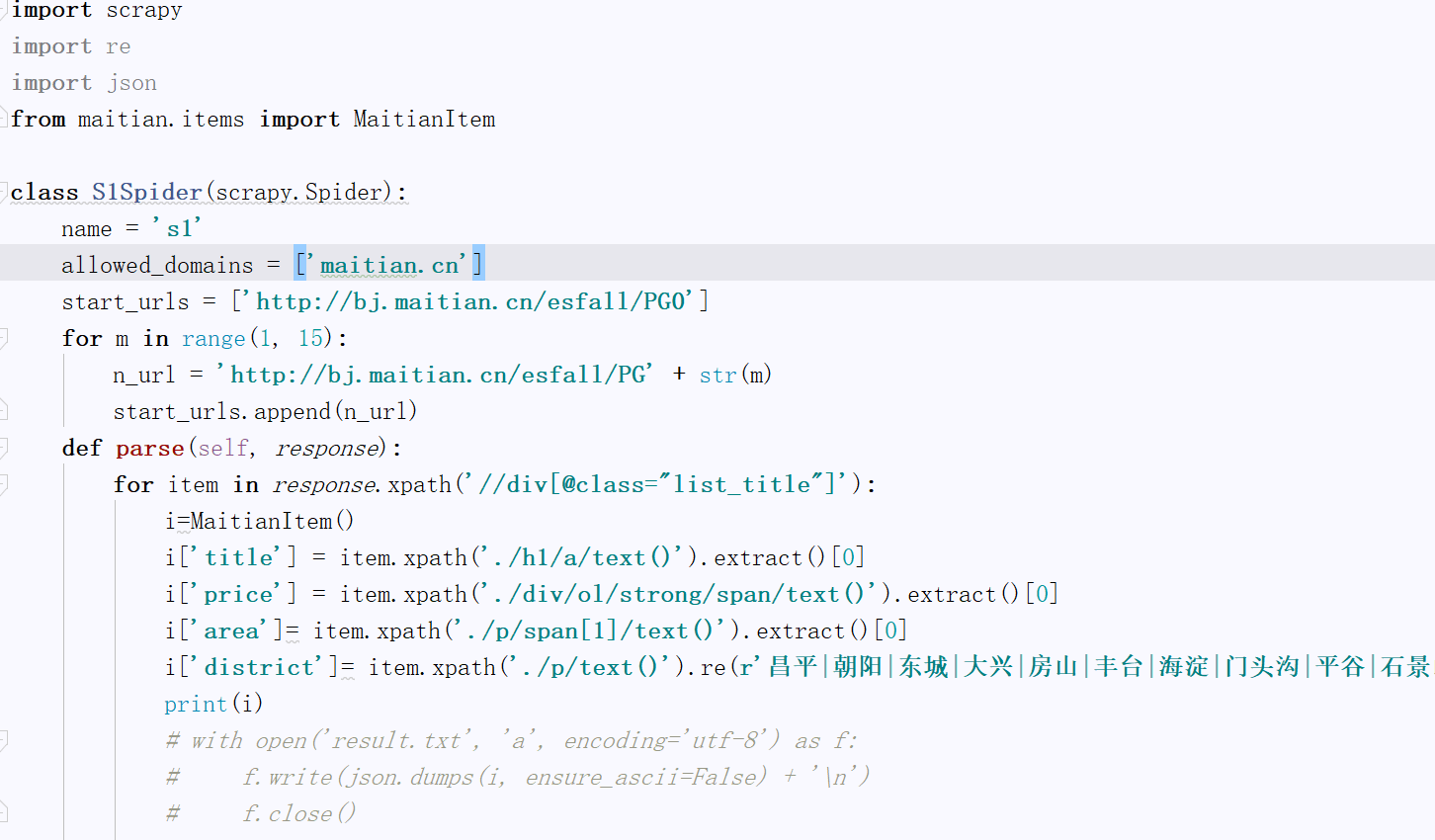
在cmd中,或terminal中cd到对应路径下,通过scrapy crawl s1运行,–nolog为不显示日志。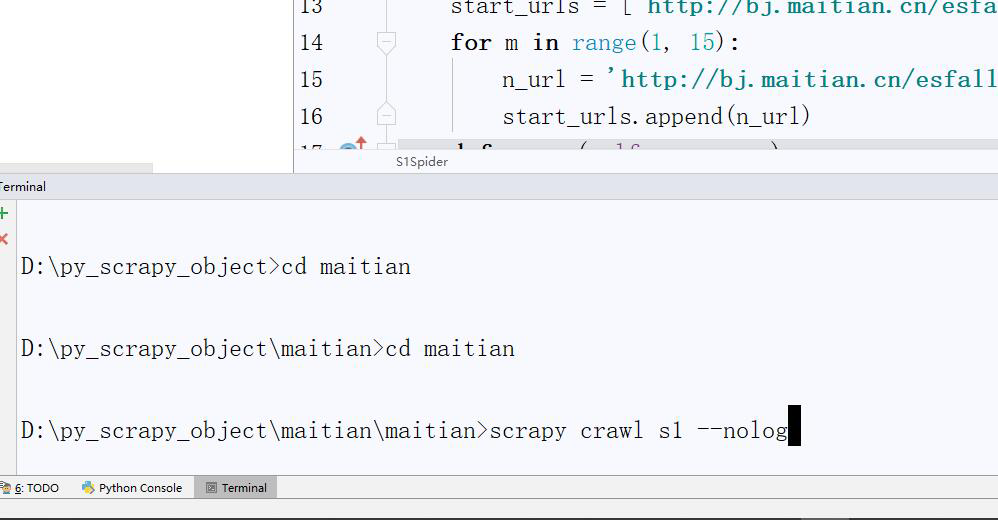

获取的结果可以存到本地文件,也可以存到mongodb,redis两个NoSQL数据库中,我没有去做,这里只是输出查看了一下,感兴趣的可以自行百度查看。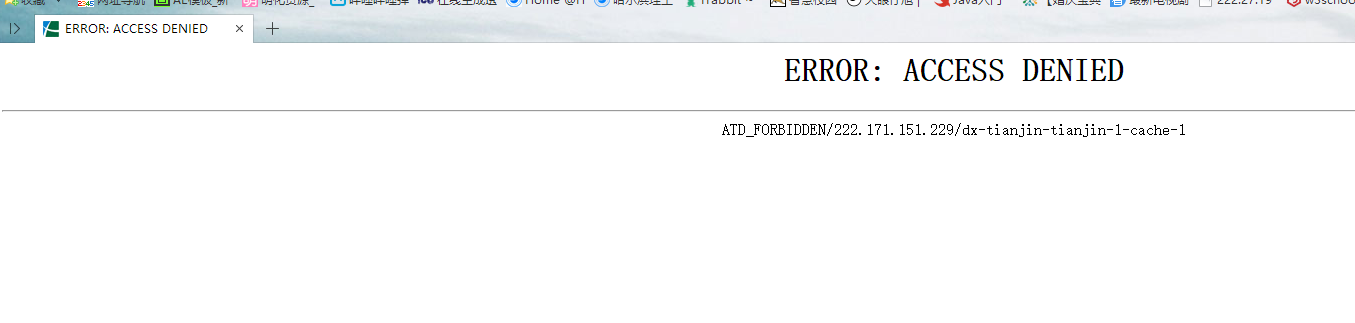
由于直接用本地ip硬上,我被暂时封了ip,但别担心,这种网站都是过段时间就更新的,过会你会发现你又可以访问了。这里提供一下如何在Scrapy框架中更改代理ip和U-A,改写scrapy中的middlewares组件,建立user-agent池和IP代理池达到反爬的效果。
最后附上文档源文件

