

Python爬虫代理ip获取、使用及查看
接上一篇文章我们来谈一下爬虫有关代理ip方面的事情
首先什么是爬虫呢?菜鸟教程中给出了如下的解释,正像Python这门语言一样,简单明了。
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
那么为什么要用代理ip呢,这就不得不提及一个机制,反爬机制,爬虫诞生之后,不意外,也是必然的会有与它相对的反爬机制,也很好理解,就是字面的意思,就是为了阻止你爬取页面信息所采取的一些手段措施,一些常见的反扒机制,在上一篇中我展示了如何解决U-A校验,及在消息头中添加user-agent,这篇文章既来说一下如何通过代理ip去解决限制访问频率这一问题。为什么要用代理ip呢,这是因为浏览器检测到你对某一页面访问频率特高,服务器会查觉到,封掉你IP,你的ip将无法继续访问这个页面,使用代理ip即可以避免你的IP被封掉,还可以通过设置多个代理ip随机调用,来解决同一IP访问频率过高问题。
1、获取代理ip
要使用代理ip,首先你要有ip才行,这里提供两个免费的代理ip网站:西刺代理,最新中国ip地址代理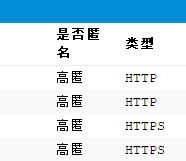
这里说一下这俩块的含义
高匿:代理IP分为四类:
(1)透明代理:虽然隐藏了本机ip,但服务器还通过一个http_forword,获取你的本地ip
(2)匿名代理:在透明代理基础上进行加工,服务器明知道你使用代理,但是他不知道你本地ip
(3)混淆代理:服务器知道你使用代理,但是你伪装了一个假的ip给服务器
(4)高匿名代理:服务器不知道你使用代理,也不知道你的真实ip
https=http+ssl 简单来说就是https比http更安全一些,详见HTTP与HTTPS的区别
这些都是一些免费的ip,所以很有可能出现已经失效,或者速度很慢的情况,如果有特殊需要可以去快代理上买。
2、爬取导入并测试代理ip
首先给一个能测试ip是否失效的软件花刺代理,使用教程,里面提到可以从txt文本中导入ip,通过之前两个免费ip的网站还要每个都复制粘贴新建文本的去导入,很麻烦,这里我基于bs4+lxml两个模块写了两个爬虫可以自动获取到一页的ip并按照可导入的形式写到txt文件中。首先说一下这两个模块怎么导入
pycharm导入方式:
依次点击File->Settings->Project Interpreter找到右边的加号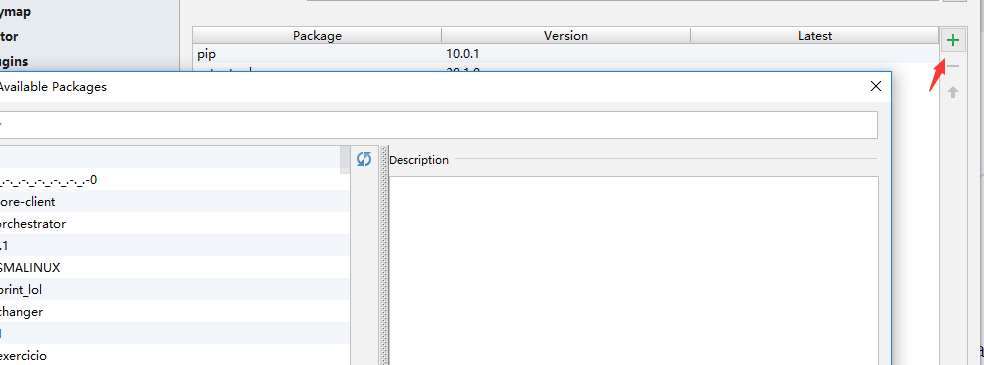
在弹窗中搜索lxml,beautifulsoup4,并点击下方的Install Package来导入模块,并保存。
其他的可以通过pip来安装具体详见Python安装Bs4几种方法,lxml同理。
然后给出两段获取ip并存入txt文档的程序,其实就是根据页面结构用bs4,lxml定位到标签然后提取其中的内容,有些类似xpath。U-A部分还是填入在上一篇文章中你获取到你本地的user-agent。
之后再有python环境的电脑中运行,会多出来一个proxy.txt文件,里面存的即是抓取到的IP地址。然后导入花刺代理软件中,验证全部。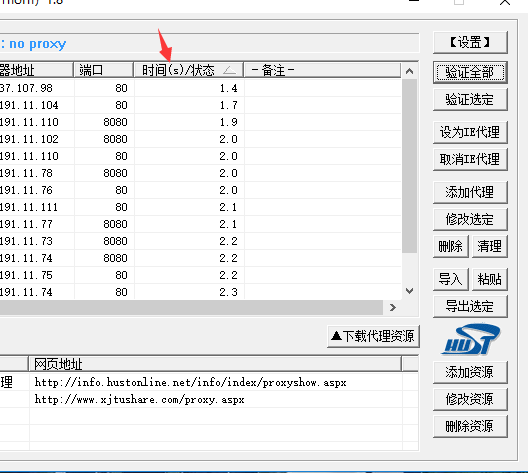
时间状态处为数字的即为可用代理ip,数字越小速度越快。若出现验证失败等无效ip可点击清理,删除失效ip。可以点击设为ie代理,然后再浏览器搜索一下查看ip,但不建议这么做,软件更改ip有可能会被Windows defender检测到并删除,这里提供一个用代码实现验证,也是真正操作如何使用代理ip的方法,在刚才的压缩包中找到测试.py,将你要用的代理ip放在‘http’:后面。也可以的添加多个,随机选取一个。访问的就是上一篇博客中我提到获取user-agent的链接,同样也可以获取本地ip,然后运行代码。可在输出中找到你用的代理ip。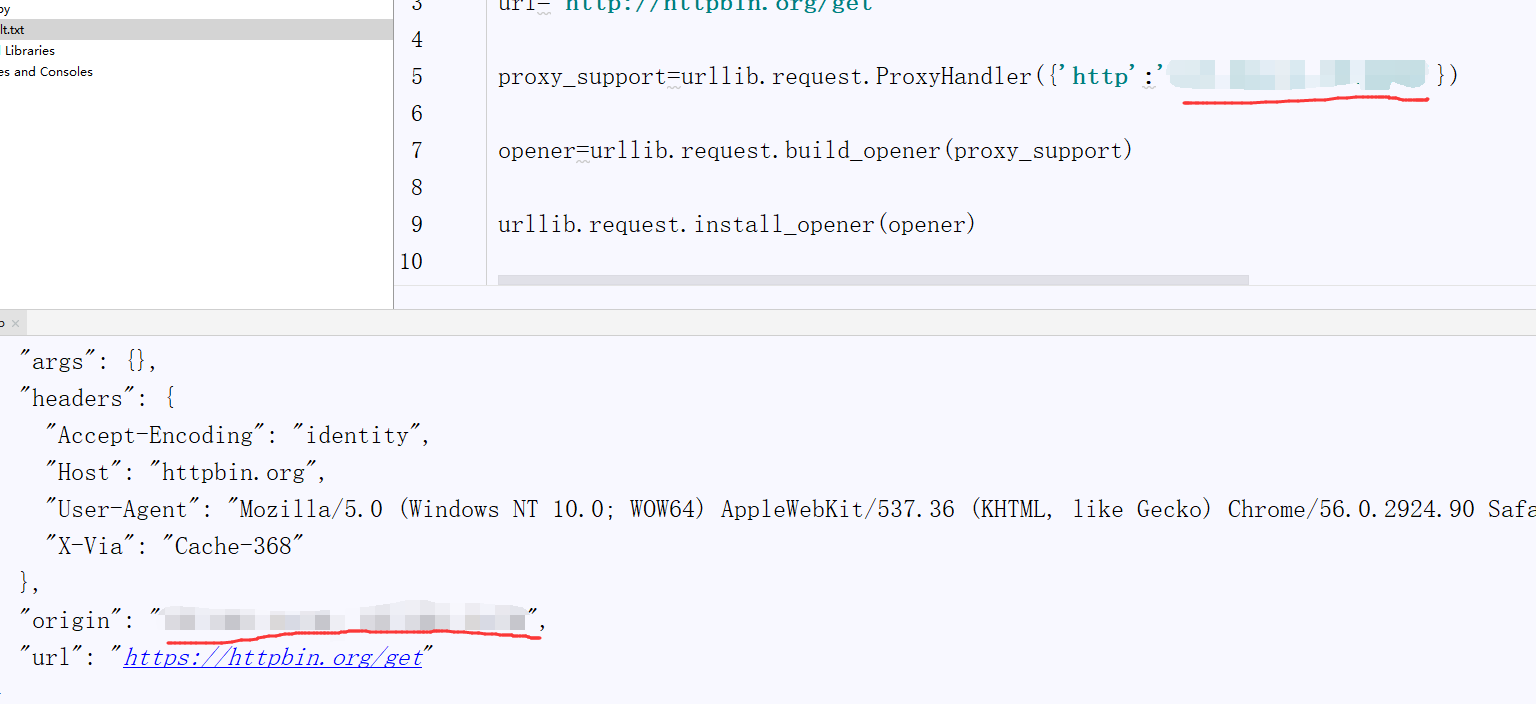

这里用的是install方法,即之后的操作全是默认在代理IP下进行的,也可以opener.open去访问链接,针对性的去代理。
至此你已经可以成功的使用代理ip去爬取页面信息了。

