

python爬虫爬取猫眼top100
最近在自学爬虫,运用正则表达式写了一个小项目
首先打开猫眼官网,依次点击榜单->TOP100榜进入到以下页面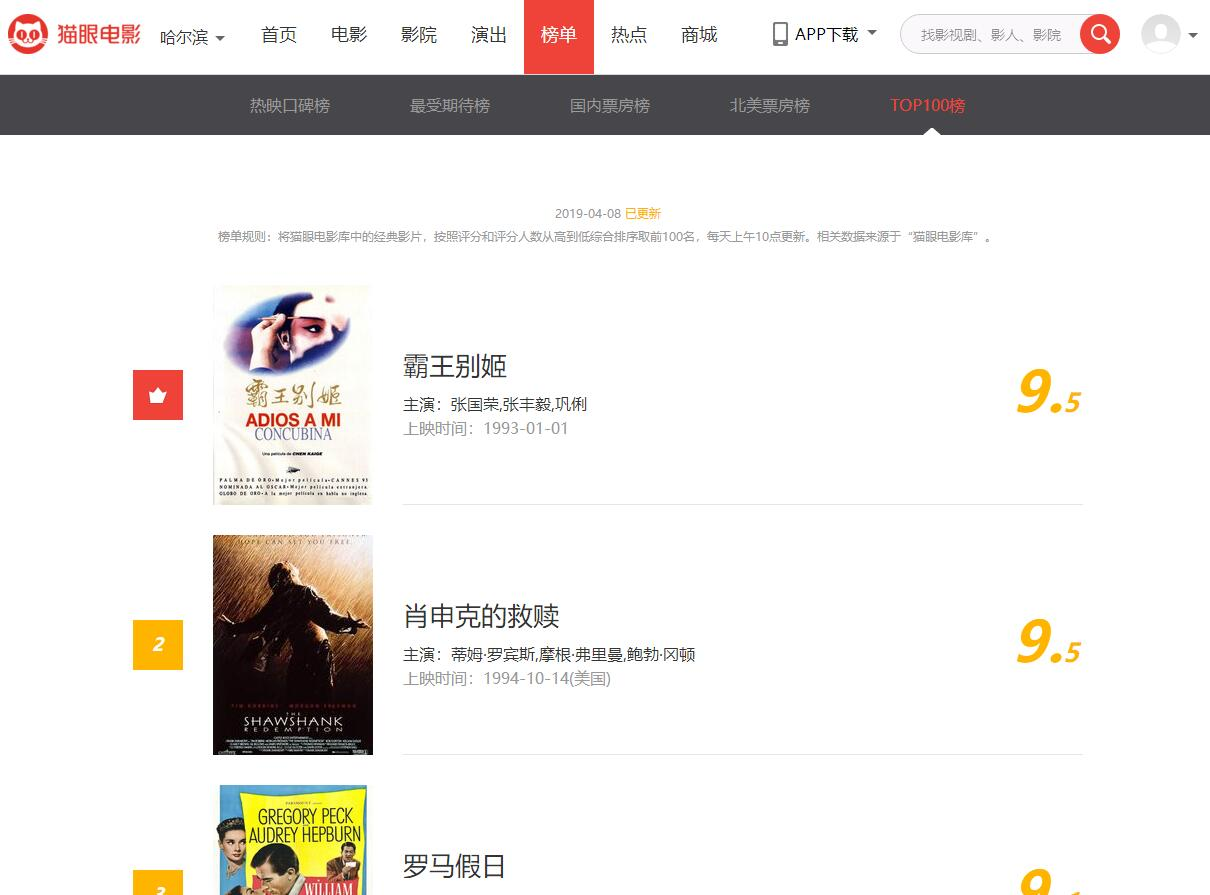
然后右键审查元素选择箭头点击页面榜单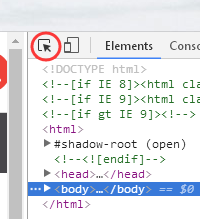
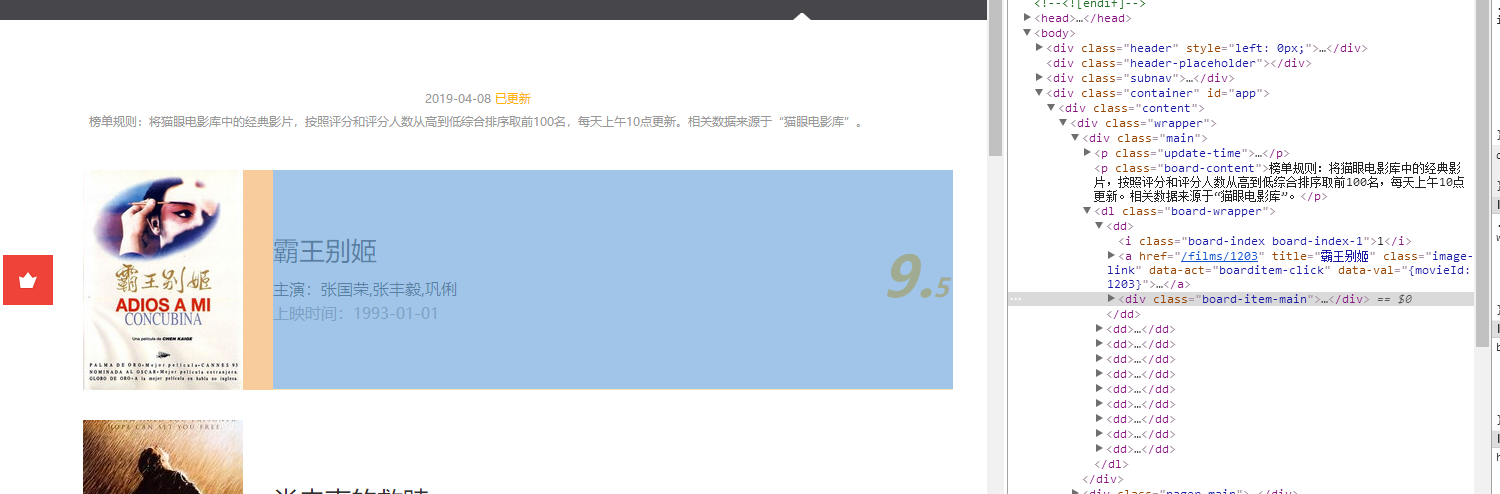

可以发现榜单中每一名的信息都存储在一个dd标签中,我提取的内容有排名(index),封面地址(image),标题(title),演员(actor),上映时间(time),评分(score)存储到一个字典中。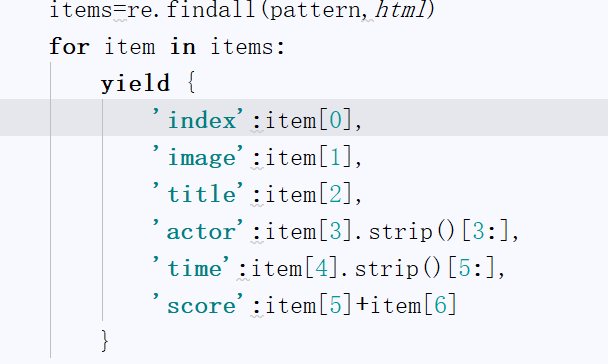
对应的这则表达式代码为
括号括取的.*?为要提取内容,返回一个列表,re.S为匹配全部,有关Python的正则表达式的内容可以详见Python正则表达式。

然后点击第二页会发现只是在链接后面加上了?offset=10,第三页?offset=20,如果改为0会发现访问的是第一页,所以要实现自动翻页只需设置循环变量i:0-10,然后i*10即为offset的值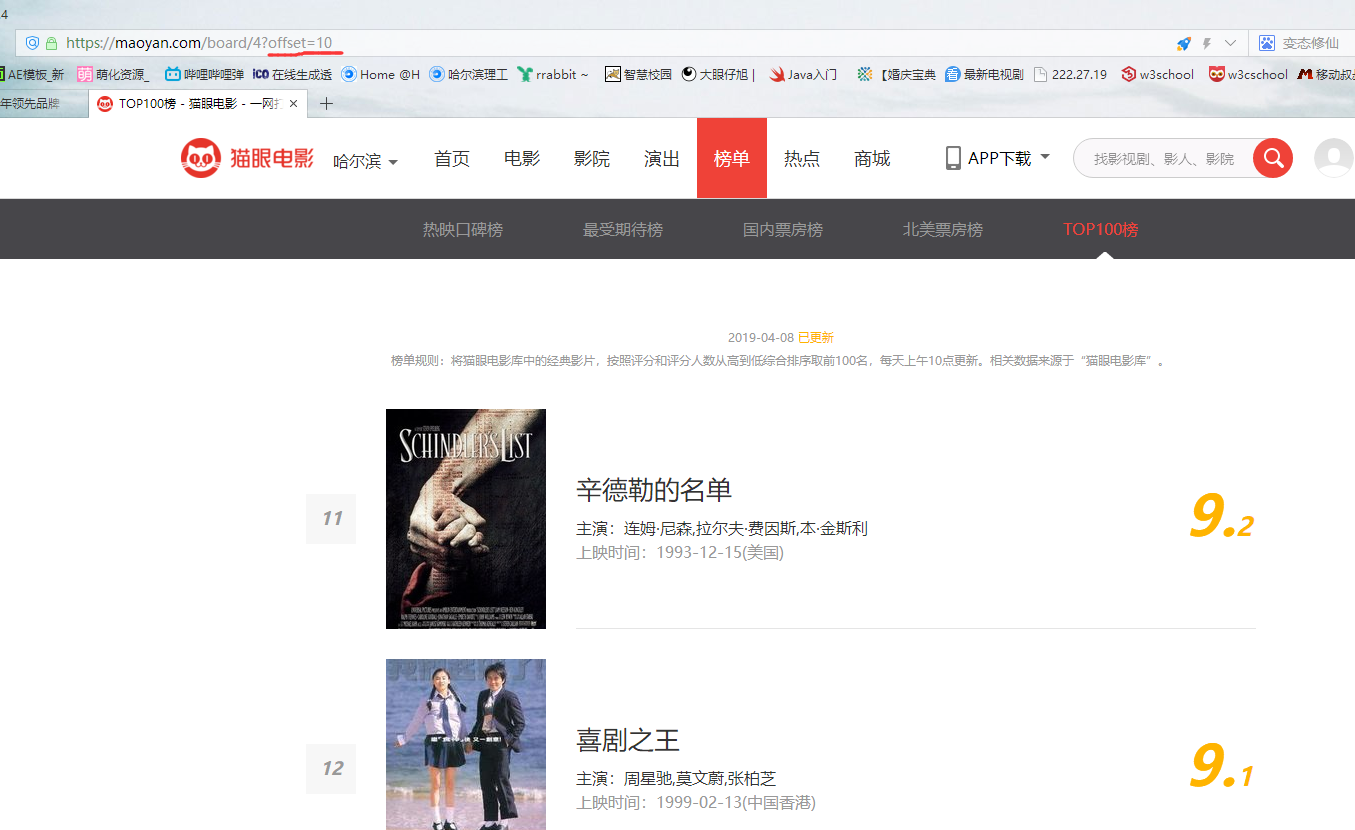
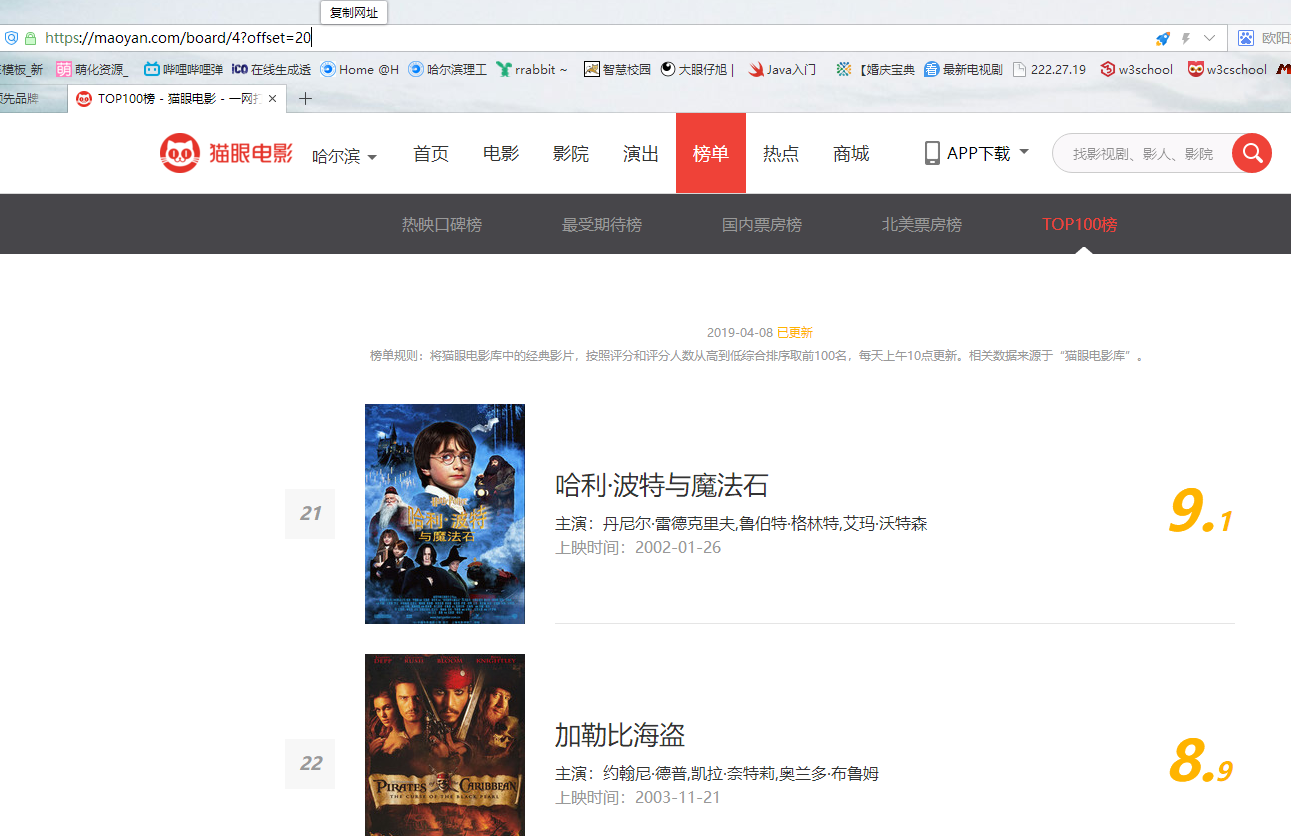
注意着几个位置的编码问题,我将最终的结果存入到result.txt文本文件中,并print输出查看了一下。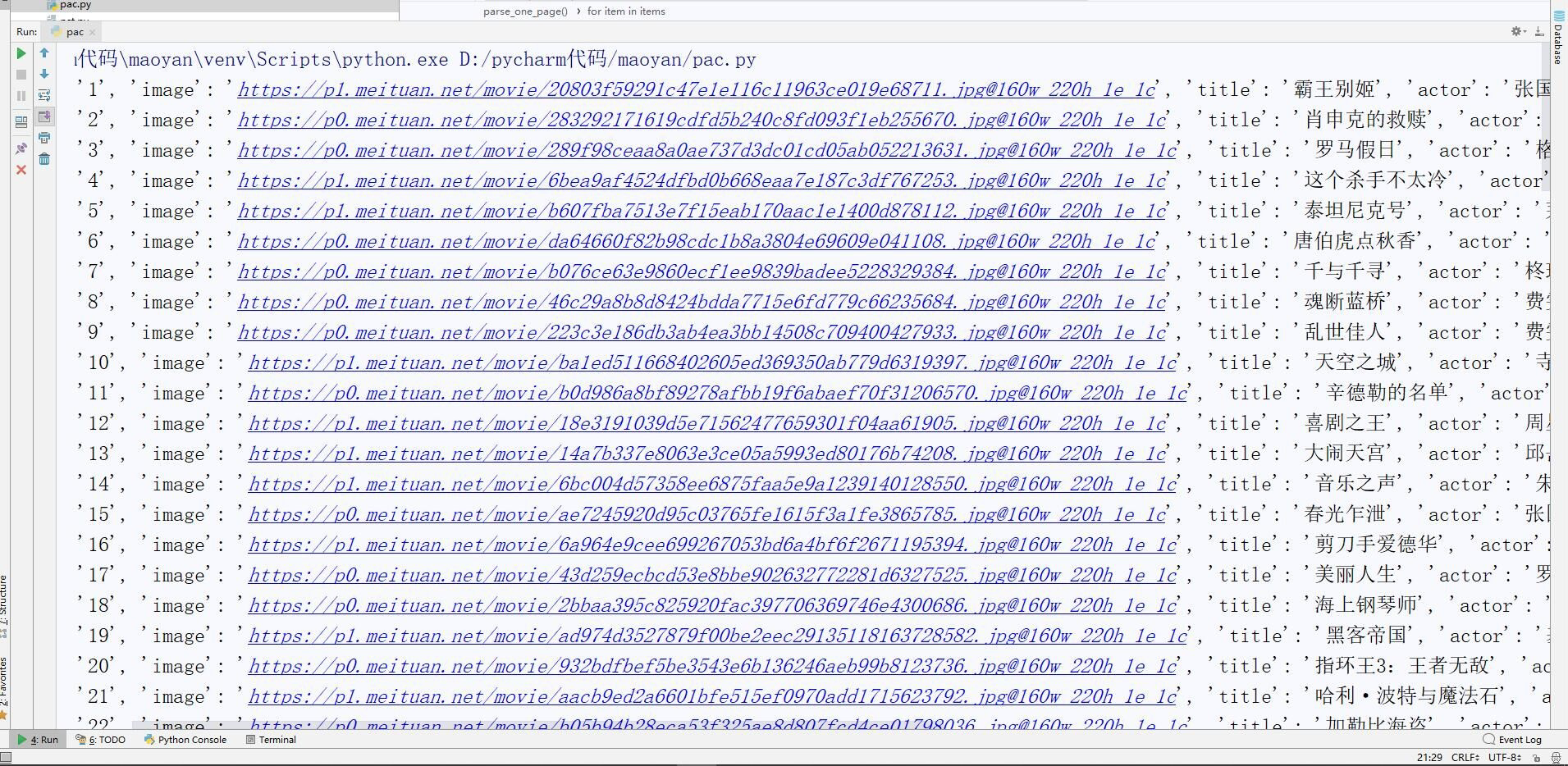
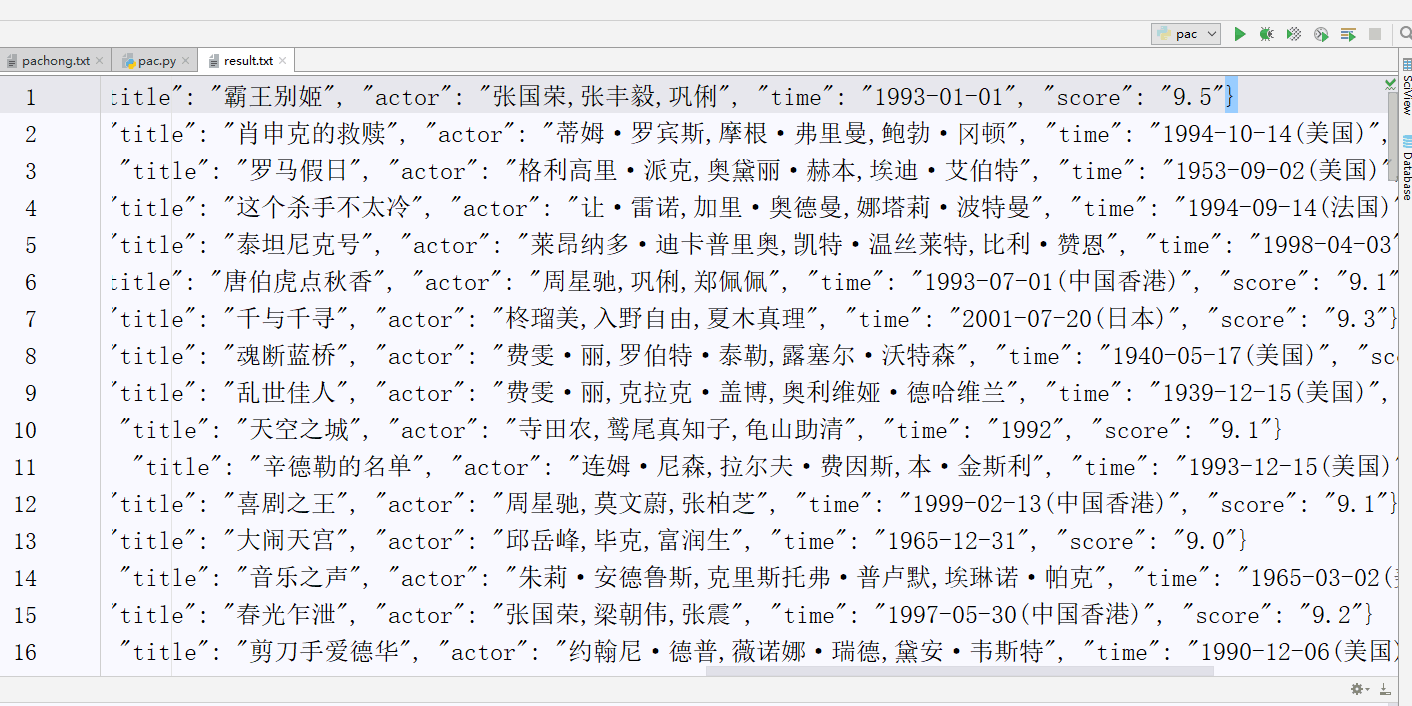
最后附上源代码
1 | import json |
关于如何查看自己浏览器的user-agent,这里我给个链接headers。然后可以以这个为模板,分析网页结构,编写对应的正则表达式来爬取其他页面的详细信息,下一篇博客介绍一下如何使用代理ip。

